Hashing
Direct address Table
we have many data structures but they are all slow at searching.
| type | time complexity |
|---|---|
| unsorted array | O(n) |
| sorted array | O(log n) |
| linked list | O(n) |
| Binary Tree | O(n) |
| Binary Search Tree | O(n) |
| Balanced Binary Search Tree | O(log n) |
| Priority (min and max) | O(n) |
to minimize the searching time we use hashing which is
O(1)
, also some people use
Direct address Table
is just same as an array.
{1,2,3,4,5,...,100}
if we need to put insert an element we put it with a key and store it let's say we need to store the number of occurrence for character
C
the number of ASCII let's assume it's 128
arr[99]
I will store in this array the number of occurrence for
c
where
99
is the key of
c
, and now if I need to access the number of occurrence letter
c
I can access it directly using
arr[99]
which is
O(1)
Introduction to hashing
the problem with this direct access is that array should have big as key sizes , to solve this problem we use hashing.
let's say we have
m
keys and
n
elements. in order to map a
key
to
element
we need an
hash function
which will take time of
n%m
which is constant
O(1)
. When we need to hash a new element to element and it have same location of an previous element it's called collision example
141%10=1
and
21%10=1
so this is collision because they have same key . The challenge with hash map is the collision.
i) better hash functions
ii) chaining (using linked list)
iii) open addressing , implemented using verious ways
a) linear probing
b) quadratic probing
c) Double hashing
chaining
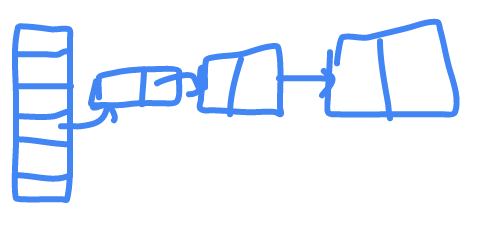
after computing the hash if there is a collision , the previous value will link to the new value.
worst case search - O(n)
worst case deletion - O(n)
average search O(1+ alpha)
average deletion O(1)
where
n
is the number of elements represented in the linked list , and
m
is the number of cells in linked list.
alpha = n/m
where alpha is the load factor.
An advantage of chained hash table over open addressing scheme is deletion is easier.
Open addressing
open addressing AKA closed hashing
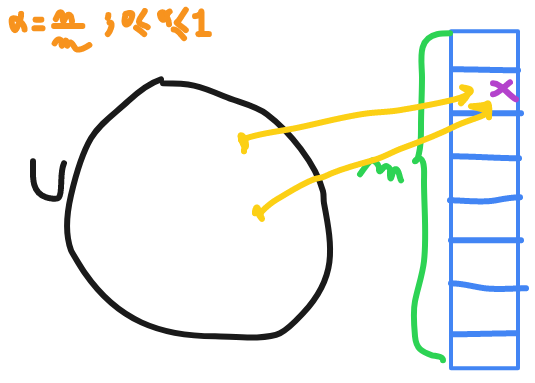
let's say we have array that can hold
m
elements it mean all the elements I need should be inside array not outside like chaining and
U
keys , where
U
is very large and
m
is limited so definitely their is a collision.
we have the load factor
alpha
which is always will be between
0
and
1
.
We resolve the collision by applying the hash function with a small modification , this is called probing second time. Probing is nothing but finding location in hash table where we need place an element.
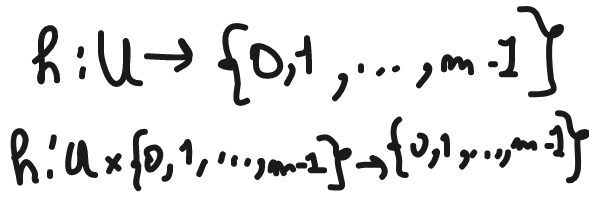
we apply the hash function if we find that the element is already picked we make a combination between
u
and finite set
[0,m-1]
the worst time here to search an element is
O(m)
because we need to visit all the table to find that element.
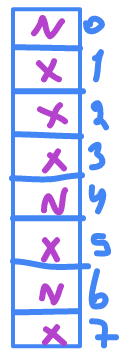
assume the
X
is mean that slot is not empty and
N
is NULL (we can put element here).
h(k) = 0
1
is NULL so I can put
k
in it.
h(k1) = 1
h(k1 , 1) = 5
h(k1 , 2) = 6
h(k1)
is
1
but
1
is not free ( their is collision ) so we run hash function again we get
5
which also is not free , so we run it again with
2
we get
6
which is NULL.
same for searching assume we have the element we need
k1
is at slot
0
h(k,0) = 2
h(k,1) = 6
h(k,2) = 3
...
h(k,7) = 0
so I take
O(m)
to find it in worst case
assume the
k1
is at slot
5
instead of
7
so if I reach
h(k,5)
and find it
NULL
I stop because I know that this element is not presented , because if it's not
NULL
the hash function will occupy it for
k1
.
This is the case if no elements being deleting . If it's deleted I will continue searching (probing). So deletion will cause a problem so I will assign an element that mean oh there is an element let's say
D
here but it is deleted , and in insertion if I find
D
I will treat it as
NULL
so I place replace it with my element.
In worst case if All elements are deleted and I need an element after them , so chaining is the best in this case.
Linear probing
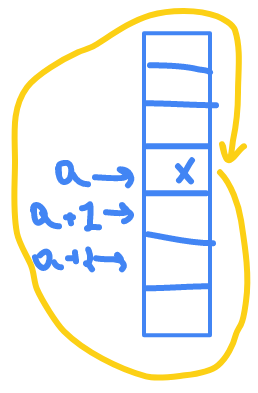
h : U --> {0 ... m-1}
if I run
h(k) = a
so index is
a
, if
a
is not empty will I will take another hash function h prime
h'(k,i)=(h(k)+i) mod m
which is
h'(k,1) = ( h(k)+1) mod n = (a+1) mod m = a+1
and
h'(k,2) = ( h(k)+2) mod n = (a+2) mod m = a+2
it's called linear probing because if the element at
a
is occupied it try
a+1
if it also occupied it will try
a+2
if it reach
m
it will start again from
0
to
a
so if it start at
1
it will start from
1
and end at
0
{1,2,3 ... m-1 , 0}
if it start at
k
it will end at
k-1
the number of prob sequences is
m
. if 2 elements have the initial prob is the same it's called secondary clustering. Primary clustering is if a continuous block of memory is sequentially occupied it mean from
a
to
a+k
is filled , so the probability of inserting an element will be
k+1/m
the worst search is
O(m)
but the average is constant
O(2.5)
their is a lot of proofs but they are hard and contain a lot of advanced probability theorems.
Quadratic probing
h'(k,i) = ( h(k) + c1*i + c2 i*i ) mod m
the problem with quadratic probing is that we need to choose
c1 , c2 and m
in such a way that
h'(k,i)
will examine entire table.
Double hashing
h'(k) = ( h1(k) + i * h2(k) ) mod m
if 2 elements have the sameh1
,
h2
probably will not be the same
selection of
h2(k)
The secondary hash function
h2(k)
it should never yield an index of zero
it should cycle through the whole table
it should be very fast to compute
it should be pair-wise independent of
h1(k)The distribution characteristics of
h2(k)are irrelevant. It is analogous to a random-number generator - it is only necessary thath2(k)be ’’relatively prime’’ tom.
In practice, if division hashing is used for both functions, the divisors are chosen as primes.